Se você me segue pelo Twitter ou Facebook já deve ter percebido que semana passada só tive um assunto: /dev/All. E não é pra menos: faz muito tempo que não me envolvo (e me divirto) tanto assim com um projeto profissional.
Apenas para lembrar: /dev/All é um agregador de blogs sobre TI/desenvolvimento de software/arquitetura/coisas tech e também um podcast cujas gravações começam a partir de amanhã (mais sobre o aspecto “podcast” semana que vêm).
A ideia original
Eu queria muito algo que pudesse ler no caminho para o trabalho. Como a esmagadora maioria do que leio envolve TI, e não há bons agregadores de blogs nacionais, por que não criar um? Primeira surpresa: descobri que pouquíssimas pessoas usam /dev/All em seus celulares, ou seja, poucos o vêem assim:
A primeira versão (0.1) era focada apenas em dispositivos móveis, por isto era tão ruim no desktop (naquele momento eu realmente acreditava que as pessoas só o usariam como eu o faço (indo para o trabalho).
Mas aí percebi que podia ir além: semana passada ficamos (eu, Pedro Campos ( estagiário da itexto) e Nanna) em cima do projeto: nisto saíram 15 releases, muitas vezes dois, três, quatro, cinco por dia. Neste post vou contar o que fizemos e o que mudou agora com o release 1.0. :)
As maiores dificuldades
Leitura de feeds
Se você é um usuário mais antigo do Grails Brasil talvez se lembre de uma antiga seção do site chamada “Blogs”. Foi o primeiro agregador de blogs que escrevi: mas como não haviam tantos blogs sobre o assunto na época, acabou perdendo o estimulo e matei o site.
Engraçado como me esqueci do quão complicado pode ser a escrita de um bot que leia feeds. Parece fácil em um primeiro momento: você irá apenas escrever um crawler que lerá documentos nos formatos XML (RSS e Atom), certo? Errado: a coisa é muito mais complicada do que aparenta.
Eu diria que uns 80% do nosso tempo foi melhorando o crawler. Por mais incrível que pareça há feeds que misturam RSS com Atom, alguns não implementam 100% do padrão, outros estabelecem seu próprio (Medium mesmo é um dos mais chatos).
Então implementamos uma biblioteca Java apenas para ler feeds – que devemos inclusive liberar o código no GitHub da itexto em breve pois acredito que muita gente deve sofrer com os problemas que enfrentamos (ROME não nos atendeu por ser muito mais complexo do que precisávamos).
Outro ponto importante: ter o extrator de posts como um processo independente do site principal. Isto nos permite corrigir e aprimorar o crawler sem precisarmos prejudicar a experiência final do usuário. Por esta razão criamos um projeto independente chamado “Feed Hunter”, que é quem alimenta o /dev/All hoje (falaremos mais sobre a arquitetura dele no futuro).
Ouvir os usuários
Não bastava apenas ter um agregador de blogs na rede: tem de ter conteúdo. Por esta razão Pedro entrou em contato com inúmeros autores durante a semana e o resultado foi positivo: todo dia você encontra bons posts no /dev/All, e o número de autores não para de crescer (temos 57 até a escrita deste post, e até o final da semana que vêm com certeza teremos mais de 100).
Então durante a semana acabamos aprendendo um pouco mais a respeito do que realmente estávamos fazendo. Foi uma experiência extremamente enriquecedora.
Ser mobile first é fácil: mobile e desktop, não
Apesar de termos alguns designers para os quais terceirizamos nossas demandas, decidimos usar esta experiência para treinarmos o que sabemos (ou achamos que sabemos) sobre design responsivo.
Confesso que ainda não estou 100% satisfeito com o nosso comportamento no desktop: ainda há um vácuo a ser preenchido pelo conteúdo do podcast que me incomoda. Mas isto deve ser resolvido nesta semana.
O que há de novo na versão 1.0
Novo crawler
Nesta semana você deve ter notado que diversos posts exibiam em seus sumários tags HTML e, em outros casos, simplesmente não mostravam nada. Isto se deu por causa dos motivos que citei acima. Sendo assim trabalhamos bastante em um novo crawler para resolver estes problemas.
Para minimizar o tempo de downtime do site quando precisamos atualizar este componente, hoje ele é executado como um processo completamente independente. Além disto, também vamos liberar o código fonte para que outras pessoas possam tirar proveito das coisas que aprendemos (e estamos aprendendo) neste trabalho.
Um dashboard para os blogueiros
Havia uma ausência (adorei esta frase) notória no /dev/All: você podia se cadastrar mas não podia alterar seus dados ou do seu blog. Notou isto? Este não é mais o problema: neste release estamos liberando um dashboard para todos os blogueiros que lhes permitem acompanhar a popularidade do que escrevem, tal como pode ser visto na imagem abaixo:
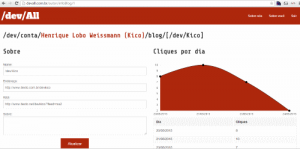
Hoje você pode ver quantos cliques por dia seu blog recebe, mas até o final da semana uma série de outras estatísticas estarão disponíveis como, por exemplo, que horas as pessoas acessam seu blog.
De onde veio esta ideia? Por que queremos te incentivar a escrever e também por que acompanhando os acessos do /dev/All vimos que as pessoas estavam clicando (e muito!) nos links que expomos! Então, por que não fornecer estas informações aos blogueiros.
Visando garantir sua privacidade, o usuário só possuí acesso aos blogs que possuí.
Ferramenta de busca

Esta foi outra coisa que muitos usuários pediram (e que era uma falta absurda), sendo assim, a incluímos no site. Agora você pode executar consultas no site.
O próximo passo é a categorização dos posts através do próprio crawler: algo no qual já estamos trabalhando. Ele será capaz de descobrir qual o assunto do post através da análise do texto (isto também vai pro GitHub).
E o futuro?
O próximo passo será a publicação do podcast e as melhorias subsequentes em nosso crawler. Claro: novas seções poderão surgir no site, mas neste momento o objetivo é fornecer ferramentas gratuitas para blogueiros e bons posts para que possamos ler.
Haverá também um RSS do /dev/All em breve, provavelmente esta semana. E agora volto a escrever a Semana Groovy :)
Qualquer dúvida ou sugestão, basta entrar em contato conosco! Espero que vocês curtam tanto o /dev/All quanto nós estamos amando construí-lo.
Vai ter/tem link para rss?
Yeap! Esta semana!
Oi Kico!
E se tivesse uma espécie de ranqueamento? Onde poderia ser levado em conta o número de acessos a um determinado post e notas que os próprios usuários dessem para cada post?
Só uma sugestão :)
Outra coisa, não seria melhor os posts abrirem em uma outra janela?
Abraço e parabéns!!!
Oi Paulo, obrigado!
Na realidade, já estamos prevendo isto já faz algum tempo, e a coisa vai se materializando aos poucos. Primeiro no dashboards dos blogueiros, aonde eles vêem o número de cliques em seus blogs.
O segundo ponto é exatamente este, com uma pequena diferença que ainda é surpresa mas, acredito, vocês irão gostar. :)
Sobre abrir o post em uma outra janela. Esta é uma grande questão: em um dispositivo móvel, não fica tão legal, por isto não o incluímos. Em um ambiente desktop, a coisa fica mais gerenciável.
A solução que estamos planejando para isto é algo um pouco melhor, que una o melhor dos dois mundos. Estamos trabalhando em uma interação entre os leitores e autores que irá permitir algo que é um meio termo. :)
Kico, deveria categorizar os sites para facilitar as buscas da galera. Acho que seria legal! Valeu!
Oi Deyvison, o próximo release do nosso crawler vai fazer exatamente isto, obrigado pelo toque!
Congrats pelo projeto!
Trabalhar com feed é um inferno mesmo, e piora ainda mais quando vai trabalhar com midia. Sofro horrores no meu projetinho de podcast, volta e meia algum podcast inventam uma maneira diferente de publicação ai lá vai eu ter que ajustar o algoritmo de sincronização.
Como que você tratou a mudança de endereço, e alteração nos links dos artigos?
Oi Emílio, obrigado!
Bom: ainda não aconteceu! :D
Hahaha então já vai se preparando, acontece mais do que pode imaginar… ;D